你確定 SQL 查詢都是以 SELECT 開(kāi)始的�?
很多 SQL 查詢都是以 SELECT 開(kāi)始的�。
不過(guò),最近我跟別人解釋什么是窗口函數(shù)�����,我在網(wǎng)上搜索”是否可以對(duì)窗口函數(shù)返回的結(jié)果進(jìn)行過(guò)濾“這個(gè)問(wèn)題��,得出的結(jié)論是”窗口函數(shù)必須在 WHERE 和 GROUP BY 之后�����,所以不能”。
于是我又想到了另一個(gè)問(wèn)題:SQL 查詢的執(zhí)行順序是怎樣的?
好像這個(gè)問(wèn)題應(yīng)該很好回答��,畢竟自己已經(jīng)寫(xiě)了上萬(wàn)個(gè) SQL 查詢了�����,有一些還很復(fù)雜����。但事實(shí)是,我仍然很難確切地說(shuō)出它的順序是怎樣的�����。
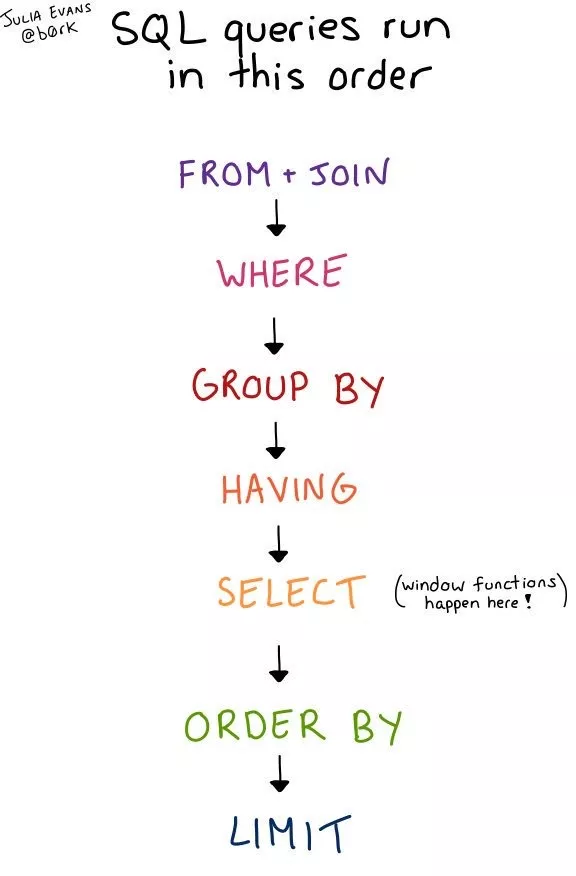
SQL 查詢的執(zhí)行順序
于是我研究了一下��,發(fā)現(xiàn)順序大概是這樣的����。SELECT 并不是先執(zhí)行的,而是在第五個(gè)����。
這張圖回答了以下這些問(wèn)題
這張圖與 SQL 查詢的語(yǔ)義有關(guān),讓你知道一個(gè)查詢會(huì)返回什么�����,并回答了以下這些問(wèn)題:
可以在 GRROUP BY 之后使用 WHERE 嗎?(不行��,WHERE 是在 GROUP BY 之后!)
可以對(duì)窗口函數(shù)返回的結(jié)果進(jìn)行過(guò)濾嗎?(不行��,窗口函數(shù)是 SELECT 語(yǔ)句里��,而 SELECT 是在 WHERE 和 GROUP BY 之后)
可以基于 GROUP BY 里的東西進(jìn)行 ORDER BY 嗎?(可以�����,ORDER BY 基本上是在最后執(zhí)行的��,所以可以基于任何東西進(jìn)行 ORDER BY)
LIMIT 是在什么時(shí)候執(zhí)行?(在最后!)
但數(shù)據(jù)庫(kù)引擎并不一定嚴(yán)格按照這個(gè)順序執(zhí)行 SQL 查詢�,因?yàn)闉榱烁斓貓?zhí)行查詢,它們會(huì)做出一些優(yōu)化�,這些問(wèn)題會(huì)在以后的文章中解釋。
所以:
如果你想要知道一個(gè)查詢語(yǔ)句是否合法���,或者想要知道一個(gè)查詢語(yǔ)句會(huì)返回什么��,可以參考這張圖;
在涉及查詢性能或者與索引有關(guān)的東西時(shí)��,這張圖就不適用了���。
混合因素:列別名
有很多 SQL 實(shí)現(xiàn)允許你使用這樣的語(yǔ)法:
SELECT CONCAT(first_name, ' ', last_name) AS full_name, count(*)
FROM table
GROUP BY full_name
從這個(gè)語(yǔ)句來(lái)看�,好像 GROUP BY 是在 SELECT 之后執(zhí)行的����,因?yàn)樗昧?SELECT 中的一個(gè)別名。
但實(shí)際上不一定要這樣��,數(shù)據(jù)庫(kù)引擎可以把查詢重寫(xiě)成這樣:
SELECT CONCAT(first_name, ' ', last_name) AS full_name, count(*)
FROM table
GROUP BY CONCAT(first_name, ' ', last_name)
這樣 GROUP BY 仍然先執(zhí)行����。
數(shù)據(jù)庫(kù)引擎還會(huì)做一系列檢查,確保 SELECT 和 GROUP BY 中的東西是有效的��,所以會(huì)在生成執(zhí)行計(jì)劃之前對(duì)查詢做一次整體檢查�����。
數(shù)據(jù)庫(kù)可能不按照這個(gè)順序執(zhí)行查詢(優(yōu)化)
在實(shí)際當(dāng)中��,數(shù)據(jù)庫(kù)不一定會(huì)按照 JOIN�、WHERE、GROUP BY 的順序來(lái)執(zhí)行查詢����,因?yàn)樗鼈儠?huì)進(jìn)行一系列優(yōu)化,把執(zhí)行順序打亂���,從而讓查詢執(zhí)行得更快��,只要不改變查詢結(jié)果��。
這個(gè)查詢說(shuō)明了為什么需要以不同的順序執(zhí)行查詢:
SELECT * FROM
owners LEFT JOIN cats ON owners.id = cats.owner
WHERE cats.name = 'mr darcy'
如果只需要找出名字叫“mr darcy”的貓����,那就沒(méi)必要對(duì)兩張表的所有數(shù)據(jù)執(zhí)行左連接����,在連接之前先進(jìn)行過(guò)濾,這樣查詢會(huì)快得多��,而且對(duì)于這個(gè)查詢來(lái)說(shuō)�,先執(zhí)行過(guò)濾并不會(huì)改變查詢結(jié)果。
數(shù)據(jù)庫(kù)引擎還會(huì)做出其他很多優(yōu)化���,按照不同的順序執(zhí)行查詢�����,不過(guò)我并不是這方面的專家����,所以這里就不多說(shuō)了。推薦:MySQL全面優(yōu)化�,速度飛起來(lái)。
LINQ 的查詢以 FROM 開(kāi)頭
LINQ(C# 和 VB.NET 中的查詢語(yǔ)法)是按照 FROM…WHERE…SELECT 的順序來(lái)的��。這里有一個(gè) LINQ 查詢例子:
var teenAgerStudent = from s in studentList
where s.Age > 12 && s.Age < 20
select s;
pandas 中的查詢也基本上是這樣的��,不過(guò)你不一定要按照這個(gè)順序�����。我通常會(huì)像下面這樣寫(xiě) pandas 代碼:
df = thing1.join(thing2) # JOIN
df = df[df.created_at > 1000] # WHERE
df = df.groupby('something', num_yes = ('yes', 'sum')) # GROUP BY
df = df[df.num_yes > 2] # HAVING, 對(duì) GROUP BY 結(jié)果進(jìn)行過(guò)濾
df = df[['num_yes', 'something1', 'something']] # SELECT, 選擇要顯示的列
df.sort_values('sometthing', ascending=True)[:30] # ORDER BY 和 LIMIT
df[:30]
這樣寫(xiě)并不是因?yàn)?pandas 規(guī)定了這些規(guī)則�����,而是按照J(rèn)OIN/WHERE/GROUP BY/HAVING 這樣的順序來(lái)寫(xiě)代碼會(huì)更有意義些��。不過(guò)我經(jīng)常會(huì)先寫(xiě) WHERE 來(lái)改進(jìn)性能����,而且我想大多數(shù)數(shù)據(jù)庫(kù)引擎也會(huì)這么做。
R 語(yǔ)言里的 dplyr 也允許開(kāi)發(fā)人員使用不同的語(yǔ)法編寫(xiě) SQL 查詢語(yǔ)句�����,用來(lái)查詢 Postgre、MySQL 和 SQLite�。


 贛公網(wǎng)安備 36050202000267號(hào)
贛公網(wǎng)安備 36050202000267號(hào)




